整理版本信息、下载入口和实机内容。
ETERNUM WORLD
诅咒铠甲2:灵魔女传奇
主线推进、角色事件与存档管理相互关联,很多卡关问题都和前置条件遗漏或版本兼容有关。
剧情RPG角色事件分支路线流程攻略版本说明

PC
Android
iOS
围绕剧情、角色、探索和章节推进组织内容。
汇总近期版本变化、补丁记录和站点资料。
game介绍
《诅咒铠甲2:灵魔女传奇》是一款以剧情推进和角色事件为核心的RPG作品,在中文玩家群体中一直有较高讨论度。游戏体验并不依赖单纯练级或数值成长,而是更强调章节推进、地图探索、对话选择和分支路线的整理。随着主线展开,玩家需要不断确认任务目标、回看角色关系,并在关键节点及时保存进度,才能更顺利地解锁后续事件。
本作的乐趣主要来自路线探索与剧情补完。不同场景、时间段、前置对话和关键道具都会影响事件是否触发,很多支线和回想内容也需要按章节逐步回收。PC版更适合整理存档和长时间游玩,安卓版则更需要注意安装完整性、存储空间和覆盖更新前的备份。对于喜欢剧情RPG、角色互动和分支收集的玩家来说,这款作品更适合慢慢阅读文本、分档推进,并在重要选择前保留记录,体验会更加完整。

精彩截图
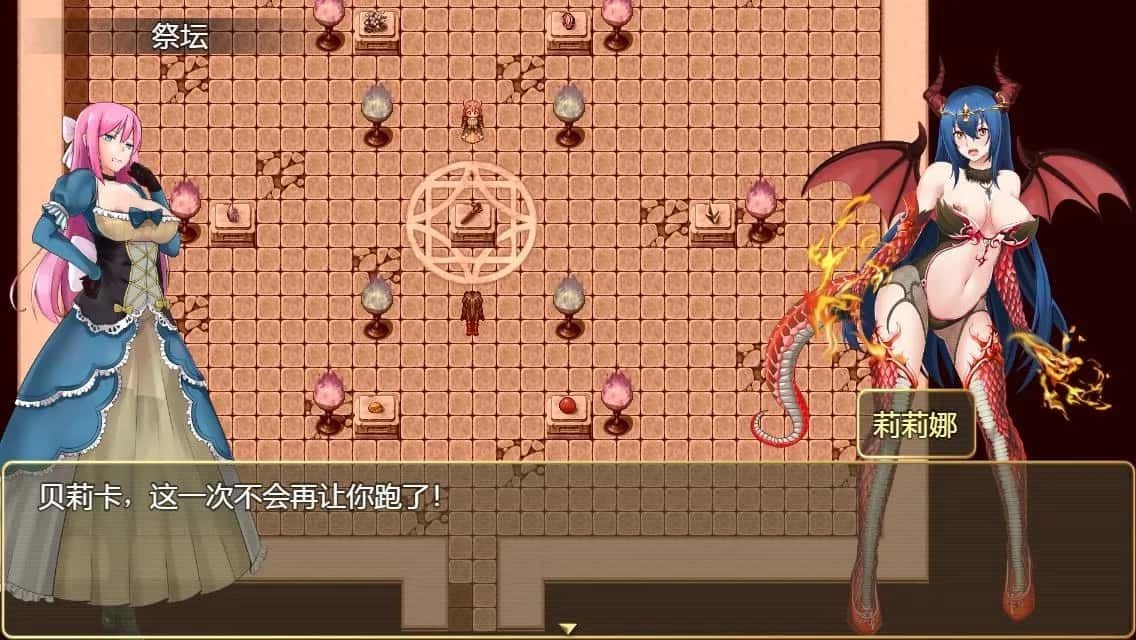
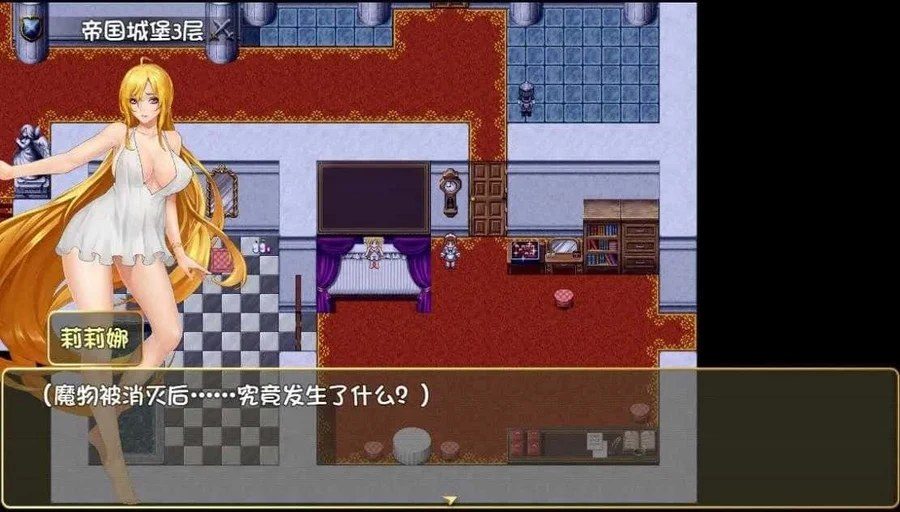

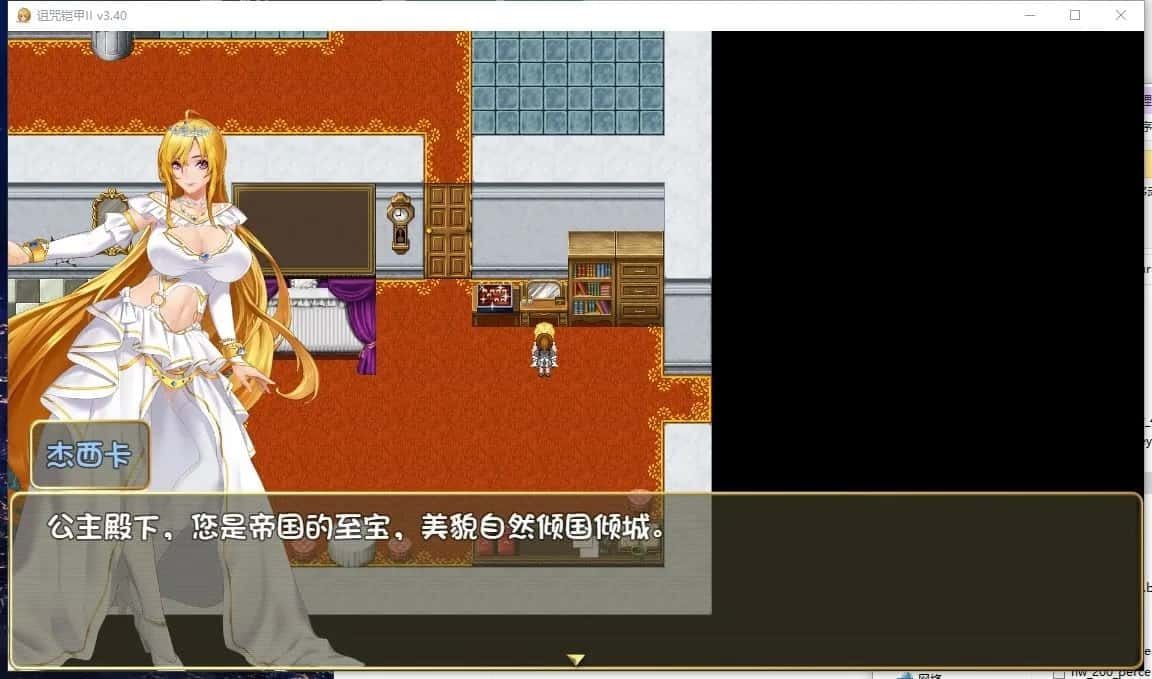
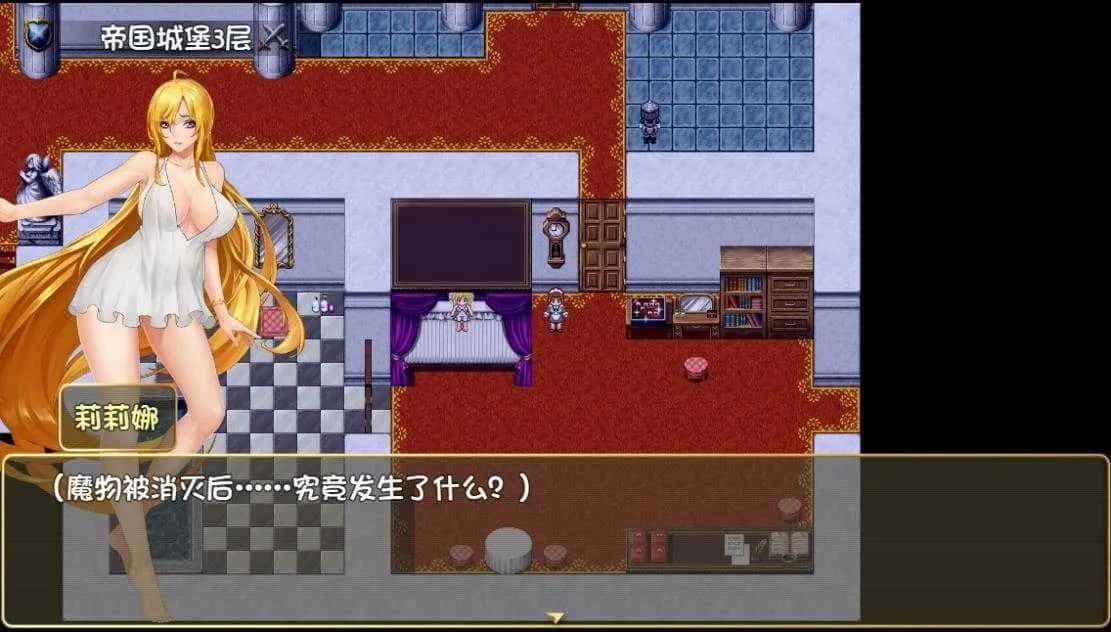


技巧指南
开始游玩《诅咒铠甲2:灵魔女传奇》时,先不要急着一路点剧情,最重要的是确认当前版本、语言内容和存档是否正常。PC版建议放在路径较短、权限较少受限的目录中,首次进入后先检查窗口模式、按键、文本速度和读档功能;安卓版则要提前确认存储空间是否充足,覆盖安装旧版本前务必备份存档,避免出现进度无法继承或事件异常。
前期最容易忽略的是说明文本和角色对话。很多玩家以为卡关来自战斗难度,实际上更常见的原因是漏掉了前置事件、没有在正确时间进入指定地点,或者主线推进后没有回头和关键角色再次交谈。每完成一个主要目标,最好把当前可进入的地点重新走一遍,重点检查旅馆、城镇、任务相关区域和曾经出现过提示的场景,有些事件就是在二次返回时才会继续触发。
中期推进要把章节节点和角色路线分开管理。比较稳妥的方式,是至少保留初始档、章节开始档、重要选择前档、角色事件完成档和通关前档。不要长期只覆盖一个存档位,否则后面想补分支、回收回想或验证触发条件时会非常麻烦。遇到某条路线迟迟不开,先回忆最近是否推进了主线、是否拿到了关键道具、是否完成上一段对话,再尝试切换场景或休息推进时间,而不是只在同一地点反复操作。
角色事件通常都有明确但不完全直白的前置条件,常见触发方式包括:完成上一阶段对话、到达特定章节、选择某类回应、在特定时段进入区域,或先完成另一名角色的关联剧情。如果想提高效率,可以简单记录已经触发的事件、当前未完成的任务和疑似关键选项。这样一旦出现卡顿,就能更快判断问题出在章节、地点、时间还是道具状态。
到了中后期,回想、相册或Gallery没有收齐时,优先从关键选择前的独立存档回头补路线,不建议直接用临时存档硬推。若更新版本后出现文本错位、菜单异常或旧档事件不触发,先用新档测试当前版本是否正常,再决定是否继续沿用旧进度。整体思路就是慢读剧情、勤存多档、按章节排查、围绕角色事件推进。只要把存档节点和前置条件理顺,大多数卡关问题都能较快解决,后续补全分支和收集内容也会轻松很多。
版本动态
版本动态
2026-06-09
中文版资料更新,补充PC版与安卓版常见运行说明。
2026-06-08
优化主线流程说明,整理章节推进、任务目标和地图探索要点。
2026-06-07
补充角色事件触发思路,包含前置对话、场景切换和关键选择提醒。
2026-06-06
更新存档管理建议,推荐保留初始档、章节档、选择前档和通关前档。
2026-06-05
整理回想收集方向,说明Gallery、相册和分支路线的排查方法。
2026-06-04
补充PC版启动注意事项,包括解压路径、运行库、权限和存档目录。
即刻下载
即刻下载